„Diese sch□nen R□ben kosten 10□.“ – Warum wird das denn nicht richtig angezeigt? Computer tun sich schwer mit Umlauten und Sonderzeichen. Das liegt an der Zeichenkodierung, ein unter Informatikern wahrlich verhasstes Thema. Aber es ist auch eine Geschichte von Technikpionieren und der zunehmenden weltweiten Vernetzung über mehrere Jahrzehnte. Und die wollen wir in diesem Teil der Internetgeschichten erzählen.

Welt der Zeichen
Zunächst müssen wir uns in einen Computer hinein versetzen. Für einen Computer haben Worte keine Bedeutung. Für ihn ist das einfach nur eine Kette von verschiedenen Buchstaben. Von denen gibt es allerdings ziemlich viele. In der deutschen Sprache haben wir die 26 Buchstaben des Alphabets plus die Umlaute „ä“, „ö“, ü“ und das „ß“. Da es Groß- und Kleinbuchstaben gibt, sind das schon 60 verschiedene Zeichen. Aber das ist noch nicht alles. Buchstaben sind nur ein bestimmter Typ Zeichen. Um ganze Texte zu schreiben, benötigen wir noch andere Zeichen. Da wären Punkt, Komma, Semikolon, Ausrufezeichen, Fragezeichen, Anführungszeichen oben und unten, Pluszeichen, Minuszeichen, Prozentzeichen, Klammer auf, Klammer zu und viele mehr.
Nicht nur im deutschsprachigen Raum gibt es viele verschiedene Zeichen. Jede Region der Welt kennt eigene. Denken wir beispielsweise an die mehreren tausend Zeichen der chinesischen, arabischen oder kyrillischen Schrift. Und das ist immer noch nicht alles, denn es gibt nicht nur sichtbare Zeichen, sondern auch unsichtbare. Zum Beispiel das „Leerzeichen“, mit dem man Worte voneinander trennt. Oder das „Neue Zeile“-Zeichen zum Trennen von Absätzen. Ohne diese unsichtbaren sog. „Steuerzeichen“ würde ein Text einfach aneinandergereiht werden und wäre für Menschen schwer lesbar. Einem Computer wäre das egal.
Zeichen aus Sicht eines Computers
In Internetgeschichten Teil #9: Einfach erklärt: Das Ding mit den Nullen und Einsen (Das Binär-System) haben wir bereits ausführlich erklärt, dass ein Computer mit solchen Zeichen nicht viel anfangen kann. Ein Computer „liest“ etwas, indem er auf einer Eingangs-Stromleitung misst, ob der Strom an oder aus ist. Und er „schreibt“ etwas, indem er auf eine Ausgangs-Stromleitung Strom an oder aus schaltet. „Strom an“ symbolisieren wir mit einer Eins, „Strom aus“ mit einer Null. Das Lesen und Schreiben eines Computers funktioniert also nur mit Nullen und Einsen.
Um das besser zu verstehen, nehmen wir einmal an, unsere gesamte Sprache bestünde nur aus vier Zeichen: Den Buchstaben „A“ und „B“, dem Leerzeichen zum Trennen von Worten und dem Punkt zum Trennen von Sätzen. Jedem Zeichen können wir eine Nummer zuweisen und die Nummer wiederum in eine Binär-Zahl übersetzen. Dies kann man in einer Übersetzungstabelle folgendermaßen darstellen:
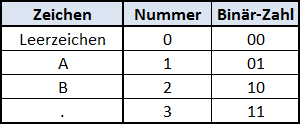
Für die vier Zeichen reichen zwei Binär-Ziffern, also 2 Bit aus. Man würde hier von einer 2-Bit-Zeichenkodierung sprechen (englisch „character encoding“, häufig einfach nur „encoding“).
Der Name der schwedischen Band „ABBA“ ist dann eine Kette aus den jeweiligen Binär-Zahlen, also: 01101001. Und auch ein ganzer Satz mit Leerzeichen und Punkt ist nichts anderes als eine Kette aus Einsen und Nullen. Der Satz „ABBA AB ABBA.“ ist: „01101001000110000110100111“. Prüft es anhand der Tabelle oben nach!
Die richtige Übersetzungstabelle
Nun wissen wir, wie ein Computer mit Zeichen umgeht, doch die Geschichte hat einen Haken: Wenn ein Computer an einen anderen Computer eine Kette von Einsen und Nullen sendet, benötigen beide die gleiche Übersetzungstabelle.
Nehmen wir zum Beispiel an, der sendende Computer verwendet die Übersetzungstabelle von oben und sendet das Wort ABBA, also „01101001“.
Auf dem Zielcomputer liegt dagegen eine andere Tabelle vor:
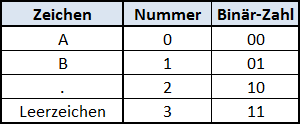
Dann wandelt der Zielcomputer das „01101001“ um in „B..B“. Mit der falschen Übersetzungstabelle kommt also nicht mehr das ursprünglich gesendete Wort heraus. (Dass dies manchmal sogar gewünscht ist, haben wir übrigens in Internetgeschichten Teil #7 – Einfach erklärt: Verschlüsselung gesehen.)
Die Mutter aller Übersetzungstabellen
Der Bedarf an einer Standard-Übersetzungstabelle, die auf möglichst vielen Computern verwendet wird, führte Anfang der 1960er zu Festlegung einer Norm. Vorreiter war hier die US-amerikanische Normierungsorganisation ASA („American Standards Association“, mittlerweile ANSI: „American National Standards Institute“). Sie schaute sich im Wesentlichen an, welche Zeichen die damals gängigen Schreibmaschinen auf ihren Tastaturen verwendeten. Zusammen mit einigen Steuerzeichen definierten sie die Mutter aller Übersetzungstabellen, genannt „American Standard Code for Information Interchange“ (deutsch: „Amerikanische Standardkodierung für den Informationsaustausch“), kurz ASCII. Insgesamt umfasst die ASCII-Tabelle 128 Zeichen, die man bis heute auch ASCII-Zeichen nennt. Die krumme Anzahl ist kein Zufall. 128 Zeichen ist die Anzahl an Zeichen, die man mit 7 Binärziffern (7 Bit) kodieren kann. Die Tabelle beginnt also bei der Binär-Zahl „0000000“ und endet bei „1111111“.
Internationale Standardisierung mit Hindernissen
Für länder-übergreifende Kompromisse ist die „Internationale Organisation für Normierung“ (warum auch immer, abgekürzt wird das „ISO“) zuständig. Diese wollte zunächst den US-Zeichensatz als internationale Referenzversion übernehmen. Doch in Zeiten des Kalten Kriegs wurde die Abstimmung darüber zum Politikum. Der Sowjetunion gefiel nicht, dass das Dollarzeichen „$“ im Zeichensatz enthalten war. Damit sie zustimmte, musste es aus dem offiziellen ISO-Standard entfernt werden. Gebracht hat es allerdings nicht viel. Die führenden amerikanischen Computerhersteller blieben bei „ihrer“ Version und exportierten damit „US-ASCII“ inklusive Dollarzeichen in die ganze Welt.
Es gab jedoch nicht nur politische, sondern auch ganz praktische Probleme mit dem amerikanischen Zeichensatz. Er beinhaltete zum Beispiel nicht unsere Umlaute, weswegen man in Deutschland besipielsweise „ä“ als „ae“ schreiben musste. Andere Länder hatten ähnliche Probleme. Die Franzosen benötigten ihre Akzente über den Buchstaben, die Norweger ihr durchgestrichenes „o“ und sogar die Briten – obwohl ja auch englischsprachig – hatten Änderungsbedarf, denn der US-Zeichensatz enthielt nicht das Symbol für das britische Pfund. Die ISO wählte daher einige weniger wichtige Zeichen im US-ASCII-Zeichensatz aus, die jedes Land in einer eigenen Version ersetzen konnte.
Bei uns ersetzte das zuständige Deutsche Institut für Normierung (DIN) die Zeichen [, \, ], {, |, } , ~ durch „Ä, Ö, Ü, ä, ö, ü“ und das „ß“. Und – welch Ironie – das in Deutschland eher unbekannte „@“ musste dem Paragraphen-Symbol „§“ weichen. Das war allerdings etwa zehn Jahre bevor Ray Tomlinson das @-Zeichen zum Bestandteil jeder E-Mail-Adresse erklärte (siehe Internetgeschichten Teil #11 – Einfach erklärt: E-Mail).
So richtig zufriedenstellend war das jedoch noch nicht. In Programmiersprachen werden eckige und geschweifte Klammern häufiger verwendet als in Briefen und Büchern. Die fehlten nun aber in den regionalen ASCII-Varianten. Das US-ASCII blieb daher weiterhin auf der ganzen Welt aktuell.
Eine einzelne Ziffer revolutioniert die Welt
Die Festlegung der ASA auf einen 7-Bit-Zeichensatz war dem damaligen Stand der Technik geschuldet. Die führenden Computer waren so gebaut, dass sie 8 Binärziffern auf einmal einlesen können. Diese Häppchen-Größe bekam den Namen „Byte“ (von englisch „bite“, was so viel wie „Biss“ oder „Happen“ bedeutet, das „y“ wurde eingebaut um Verwechslungen mit dem „Bit“ zu vermeiden). Die ASA nutzte 7 Ziffern für den Zeichensatz und ließ die achte Ziffer undefiniert. Die Computerhersteller konnten über die Verwendung selbst entscheiden. Dabei hatte man bestimmte Prüftechniken im Sinne, die Übertragungsfehler aufdecken konnten. Aber relativ schnell wurde klar, dass man das freie Bit lieber für die Aufnahme weiterer Zeichen verwenden wollte.
Ein weiteres Bit, also eine zusätzliche Null oder Eins, klingt erst einmal nicht viel. Aber tatsächlich verdoppelt sich damit die Anzahl Zeichen von 128 auf 256. Das Problem war nun allerdings, dass jeder Hersteller den zusätzlichen Platz anders nutzte. Es entstand ein enormer Wildwuchs an parallel existierenden Übersetzungstabellen. Wenn man Daten vom Computer eines Herstellers auf einen anderen übertragen musste, konnte man sich nicht sicher sein, ob alle Zeichen richtig übersetzt würden. Richtig verlässlich waren weiterhin nur die ersten 128 ASCII-Zeichen, sozusagen der kleinste gemeinsame Nenner.
8-Bit-Standardisierung mit Hindernissen
Es dauerte bis in die 80er Jahre hinein bis sich Standards zu 8-Bit-Zeichensätzen bildeten. Das war auch dringend nötig, denn das Internet stand in den Startlöchern und ohne eine gemeinsame Grundlage war die Vernetzung von Computern schwierig. Zum einen brachte IBM den ersten „PC“ auf den Markt, der sich rasend schnell als Arbeitsplatzcomputer verbreitete und mit ihm die darauf verwendete Übersetzungstabelle, die sog. „Codepage 437“. Zum anderen forcierten die europäischen Computerhersteller einen neuen ISO-Standard, in dem die wichtigsten west-europäischen Zeichen enthalten sein sollten, das sogenannte „ISO 8859-1“. Dieser wurde allerdings mit dem damals (nach IBM) zweitgrößten Computerhersteller der Welt DEC entwickelt. Und – wie könnte es anders sein – die beiden Standards waren zusammen nicht kompatibel:
Wenn jemand auf einem Computer mit Kodierung ISO 8859-1 zum Beispiel das Wort „Bär“ eingab, machte der IBM-PC daraus „BΣr“. Bei umgekehrter Richtung wurde aus „Bär“ zum Beispiel „B□r“ oder „B?r“, denn die Binär-Zahl, die IBM dem „ä“ zuwies, war im ISO-Standard nicht vergeben. Für solche Fälle war es dem jeweiligen Computerprogramm überlassen, irgendein Platzhalter-Zeichen auszuwählen.
Besserung kam mit der Verbreitung von Microsoft Windows als herstellerübergreifendes Computer-Betriebssystem. Microsoft übernahm ISO 8859-1 als „Codepage 1252“ bzw. „ANSI“, womit es faktisch in den 90er-Jahren zum weltweiten Standard wurde. Jedoch ergaben sich schon relativ schnell wieder Abweichungen: Ende der 90er Jahre wurde zum Beispiel das Euro-Zeichen „€“ eingeführt. Microsoft hatte kein Problem damit, es in der eigenen „Codepage 1252“ zu ergänzen. Alle Microsoft-Produkte kamen damit klar. Doch im offiziellen ISO 8859-1 fehlte es. Stellt euch vor, jemand erstellt auf einem Windows-Rechner eine Preistabelle und sendet sie an jemanden, der die offizielle ISO-Übersetzungstabelle verwendet. Beim Empfänger würde die Preistabelle ohne das Euro-Zeichen angezeigt.
8 Bit reichen auch nicht aus
Die ISO veröffentlichte später weitere Standard-Tabellen: ISO 8859-15 enthielt das Euro-Zeichen, ISO 8859-2 die wichtigsten mitteleuropäischen Zeichen, ISO 8859-3 bediente Südeuropa, ISO 8859-4 dann Nordeuropa, ISO 8859-5 enthielt die kyrillischen Zeichen, … kurzum: Es entstanden schon wieder etliche unterschiedliche Übersetzungstabellen. Sie hatten jetzt zwar einen offiziellen Stempel, waren aber miteinander nicht kombinierbar – außer man beschränkte sich weiterhin auf die ASCII-Zeichen, die nach wie vor in allen Tabellen den harten Kern bildeten.
Angesichts der weltweiten Vernetzung durch das Internet war aber klar: Es musste eine Übersetzungstabelle her, in der endlich alle Zeichen der Welt enthalten sind. Und das war mit 8 Bit bzw. 1 Byte pro Zeichen einfach nicht möglich.
Die weltgrößte Zeichensammlung
Verantwortlich für die Festlegung einer Übersetzungstabelle, die alle Zeichen umfasst, ist das sogenannte Unicode-Konsortium. Sie sammelt seit 1991 Zeichen aus aller Welt und legt dafür eine Nummer fest. In mittlerweile 30 Jahren wurden dem „Unicode“ 143.859 Zeichen hinzugefügt. Die ISO übernimmt alle Festlegungen des Unicode-Konsortiums und erklärt sie zur offiziellen Norm „ISO 10646“ und bezeichnet den Unicode dort als „Universal Coded Character Set“, kurz UCS. Die inoffizielle Bezeichnung „Unicode“ ist aber wesentlich gebräuchlicher.
Damit gibt es immerhin eine weltweit anerkannte nummerierte Liste aller Zeichen. Doch wie geht nun ein Computer damit um? Erst einmal kein Problem. Heutige Computer sind nicht mehr auf das Einlesen von 8-Bit-Häppchen beschränkt. Man kann also festlegen, dass jedes Unicode-Zeichen als 32-stellige Binär-Zahl kodiert wird. Das wurde auch tatsächlich gemacht, es nennt sich UTF-32 (UTF für „Unicode Transformation Format“). Aber diese Methode ist nicht besonders ökonomisch. Selbst für die normalen ASCII-Zeichen benötigt man dann 32 Bit. Man vergrößert den Speicherplatz für jedes Zeichen auf das Vierfache.
Variable Zeichenkodierung
Man steckt also in der Zwickmühle: Für gebräuchliche Texte möchte man eigentlich bei platzsparenden 8 Bit (1 Byte) bleiben. Für Sonderzeichen aus dem Unicode benötigt man aber bis zu 32 Bit (4 Byte). Daher verabschiedete man sich von den einfachen aber unflexiblen festen Längen. Eine erste variable Kodierung wurde als UTF-16 festgelegt. Hier werden die am häufigsten verwendeten Zeichen mit 16 Bit (2 Byte) codiert und nur außergewöhnliche Zeichen mit 32 Bit (4 Byte). Diese Kodierung ist speziell auf Windows-Systemen in Verwendung.
Etwas neuer ist die UTF-8-Kodierung. Sie ist nicht auf 2 oder 4 Byte festgelegt und daher noch etwas flexibler. Für die ursprünglichen ASCII-Zeichen verwendet sie nur 1 Byte. Weitere Zeichen können mit 2, 3 oder 4 Byte kodiert werden. UTF-8 ist die ökonomischste Variante und daher für die Übertragungen im Internet mittlerweile am häufigsten genutzte Kodierung.
Die variable Kodierung ist eine gute Sache, allerdings auch deutlich komplexer. Und „komplexer“ heißt in der Informatik immer „fehleranfälliger“. Ein häufiger Fehler in der Entwicklung von Computerprogrammen ist zum Beispiel, dass für Sonderzeichen zu wenig Speicherplatz vorgesehen ist. In der alten Welt konnte man fest davon ausgehen, dass ein Zeichen genau 1 Byte Speicherplatz benötigt. Doch zum Beispiel mit einem Umlaut kann ein Wort mit 10 Zeichen nun auch 11 Byte Speicherplatz benötigen. Das führt dann in der Regel zu unerwarteten Fehlermeldungen.
Noch immer keine Einigung
UTF-8, UTF-16, UTF-32 … auch sechzig Jahre nach Entstehung des ASCII-Zeichensatzes reden wir immer noch über unterschiedliche Übersetzungstabellen. So schön die Vorstellung des Unicodes auch ist, es gibt weiterhin Probleme mit verschwundenen oder falsch angezeigten Zeichen. Bleibt nur noch zu sagen: Schei□ Kodierung! 😀
 Für Fragen, Kritik oder Anregungen schickt mir gerne weiterhin Nachrichten, gebt mir Rückmeldung über die Kommentarfunktion unten oder nutzt die Facebook-Seite zum Blog.
Für Fragen, Kritik oder Anregungen schickt mir gerne weiterhin Nachrichten, gebt mir Rückmeldung über die Kommentarfunktion unten oder nutzt die Facebook-Seite zum Blog.
Und falls es Euch gefallen hat, lasst ein „Daumen-hoch“ da. 🙂